A deep dive into Custom Attributes
In IRIS v1.4.0 we introduced the concept of Custom Attributes, a way to extend the default fields of any case objects. We already published some documentation about it, but today we are exploring the full potential of custom attributes.
A basic example
Let's start with a simple example and extend the Evidences objects.
We will :
- Add a new checkbox to allow analysts to indicate whether they analyzed the evidence or not,
- Add a text field to allow them write some notes about the analysis
Heading to the attributes administration page in Advanced > Custom Attributes, we open the custom attributes for Evidences.
The window should looks like this unless you already added some custom attributes.
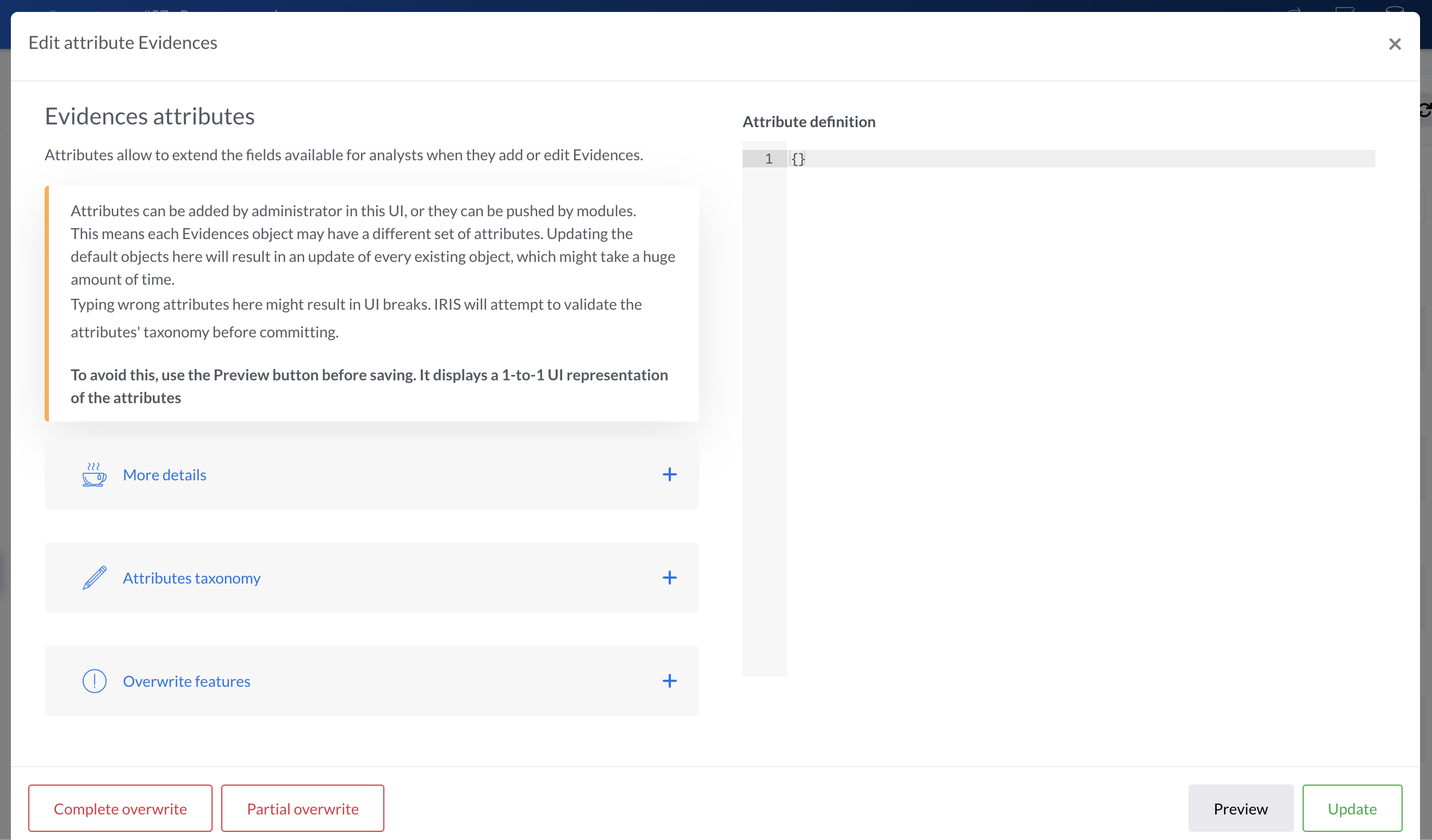
The right text input allows us to describe the custom attributes thanks to a simple JSON formatting. They are defined as follow :
- Line 2 creates a new tab in the object
- Line 3 creates a new field within this new tab
- Line 4 to 6 describes the type and default values of this new field.
Field types are predefined types, described in attributes taxonomy.
So let's translate this into our example. We want to create a new tab called "Analysis" in Evidences object, and within these two new fields :
- A checkbox "Has been analyzed"
- A text field "Analysis notes"
Checkbox is of type input_checkbox, and the text field is of type input_textfield.
Putting it all together :
Basic attribute | |
|---|---|
By setting mandatory to false, we ensure the creation/update of Evidences are not rejected if these fields are not set by the users.
value must be set to a boolean for checkbox inputs. It can be set to nothing for the text field.
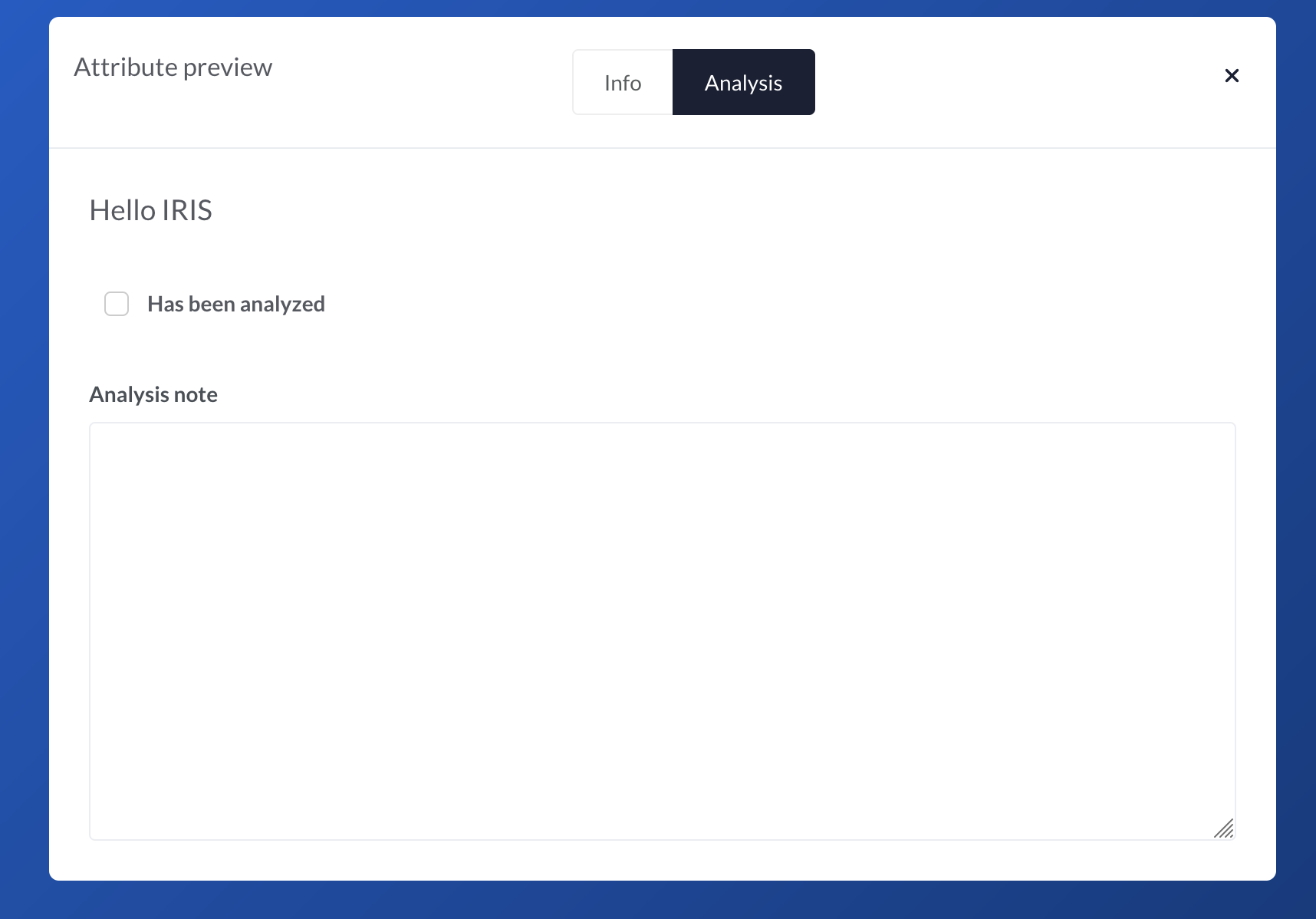
Now it's time to ensure our attributes are rendered as expected. Let's click on preview, and then on the - hopefully - new tab Analysis on the preview.
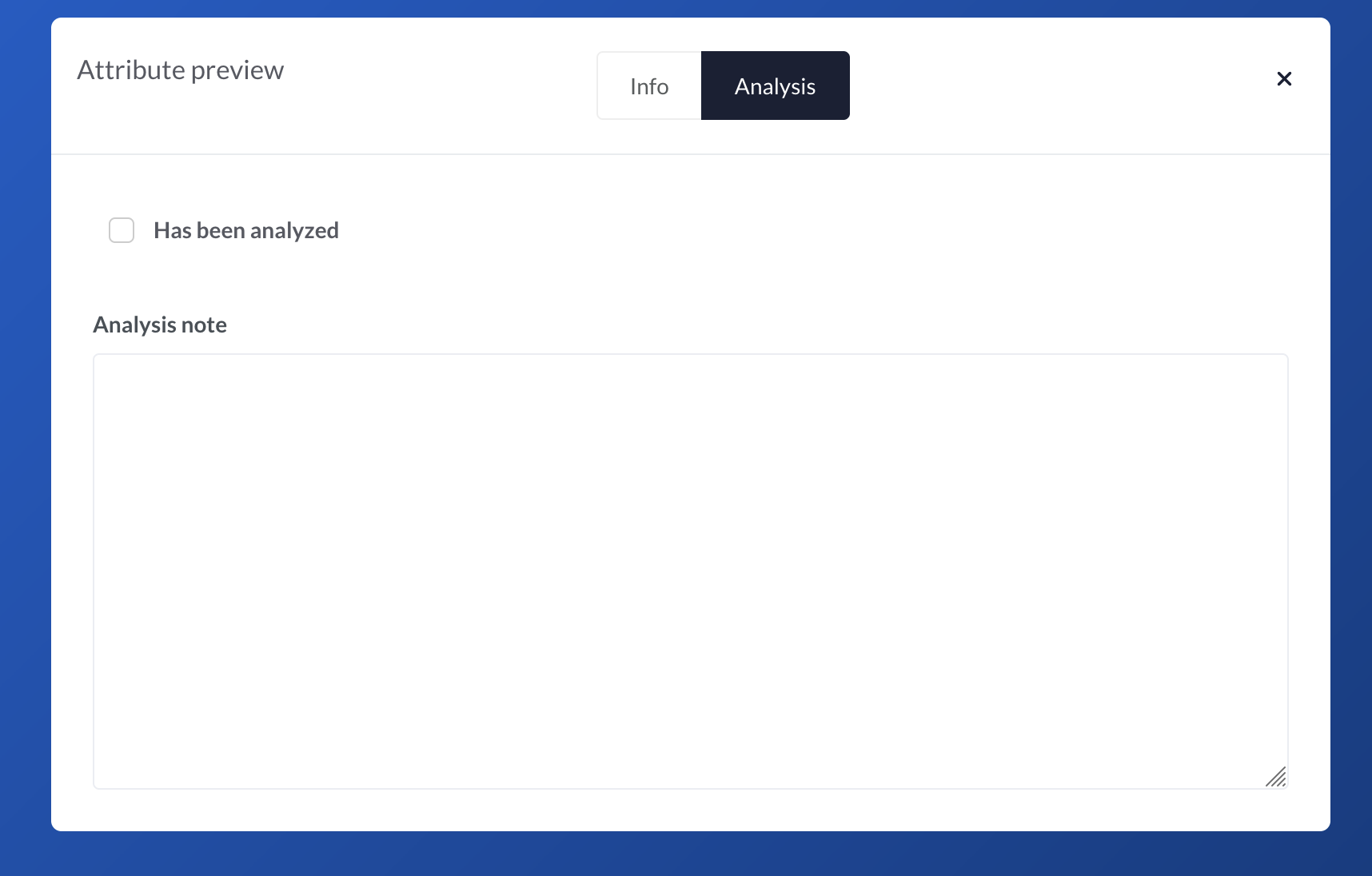
There we go!
We can now deploy our changes to the Evidence objects. Curious about how it's handled under the hood? You can take a look a the deep dive section Under the hood.
We will deploy the changes to all Evidences objects but not force the overwrite if some of them already have attributes. We close the preview and we click on Update. Depending on how many Evidences you have, this can take a little time, but once the update is finished, all Evidences objects should have our new custom attributes.
We head to the Evidence section of one of our case, click on one of them or try to add one, and we should have a beautiful new tab in our Evidence.
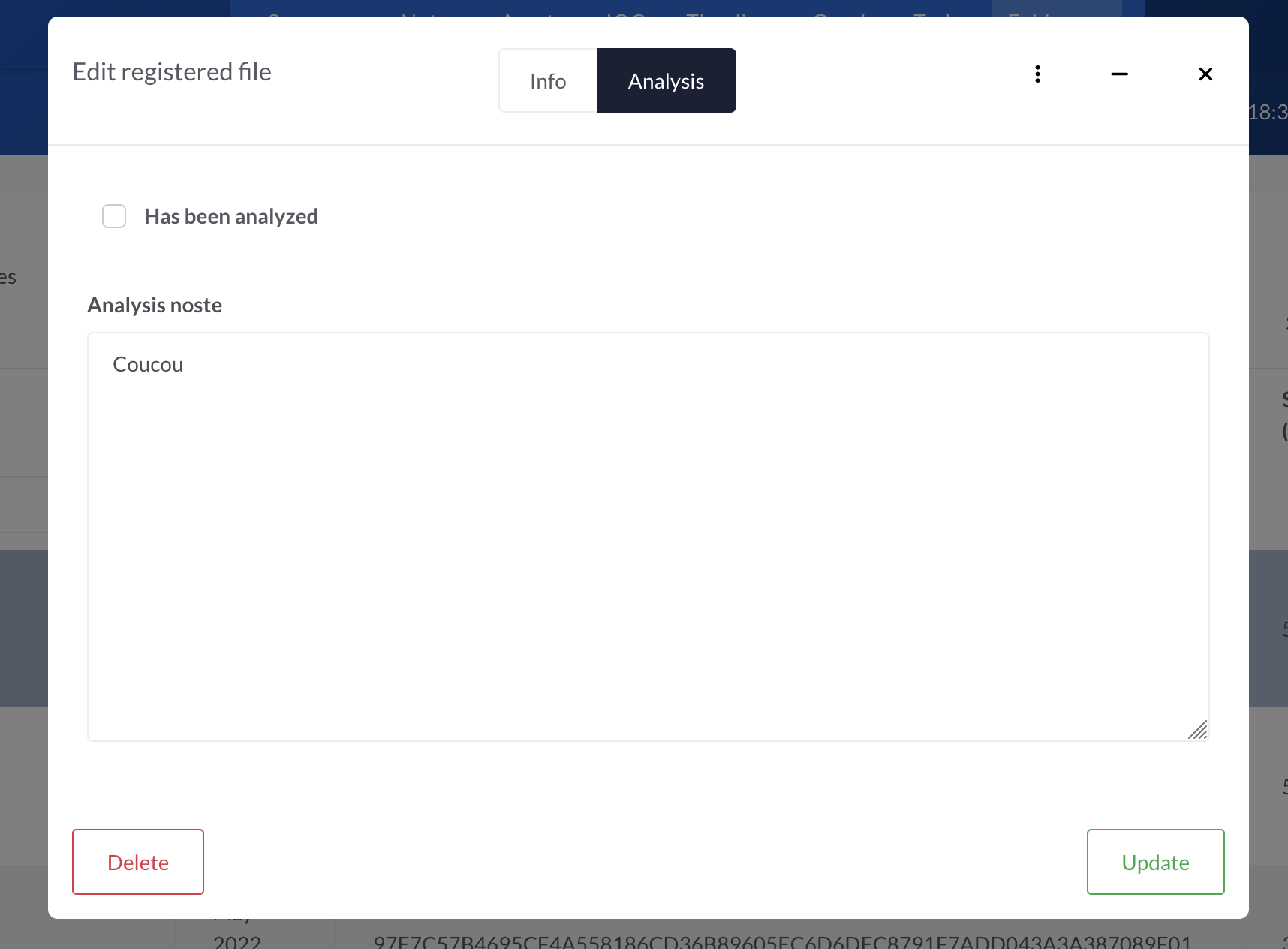
Input a few notes, check the box and click on Update. The data is now saved with the object. Time to celebrate!
Dynamic custom attributes
That's great, but now what if we want to add the possibility to specify who analyzed the Evidence? We could add a new text input, but let's make something a little more advanced by proposing a list of all the analysts on the platform.
Raw HTML fields
There is no direct way of proposing a list of analysts with standard custom attributes, however we have the powerful html type and thanks to that we can input HTML and so Javascript. HTML custom attributes are not processed by IRIS and are rendered as-is in the objects.
Let's take the previous Evidence custom attribute and add a new html entry to it, with a simple h3 entity as HTML content.
Dynamic attribute | |
|---|---|
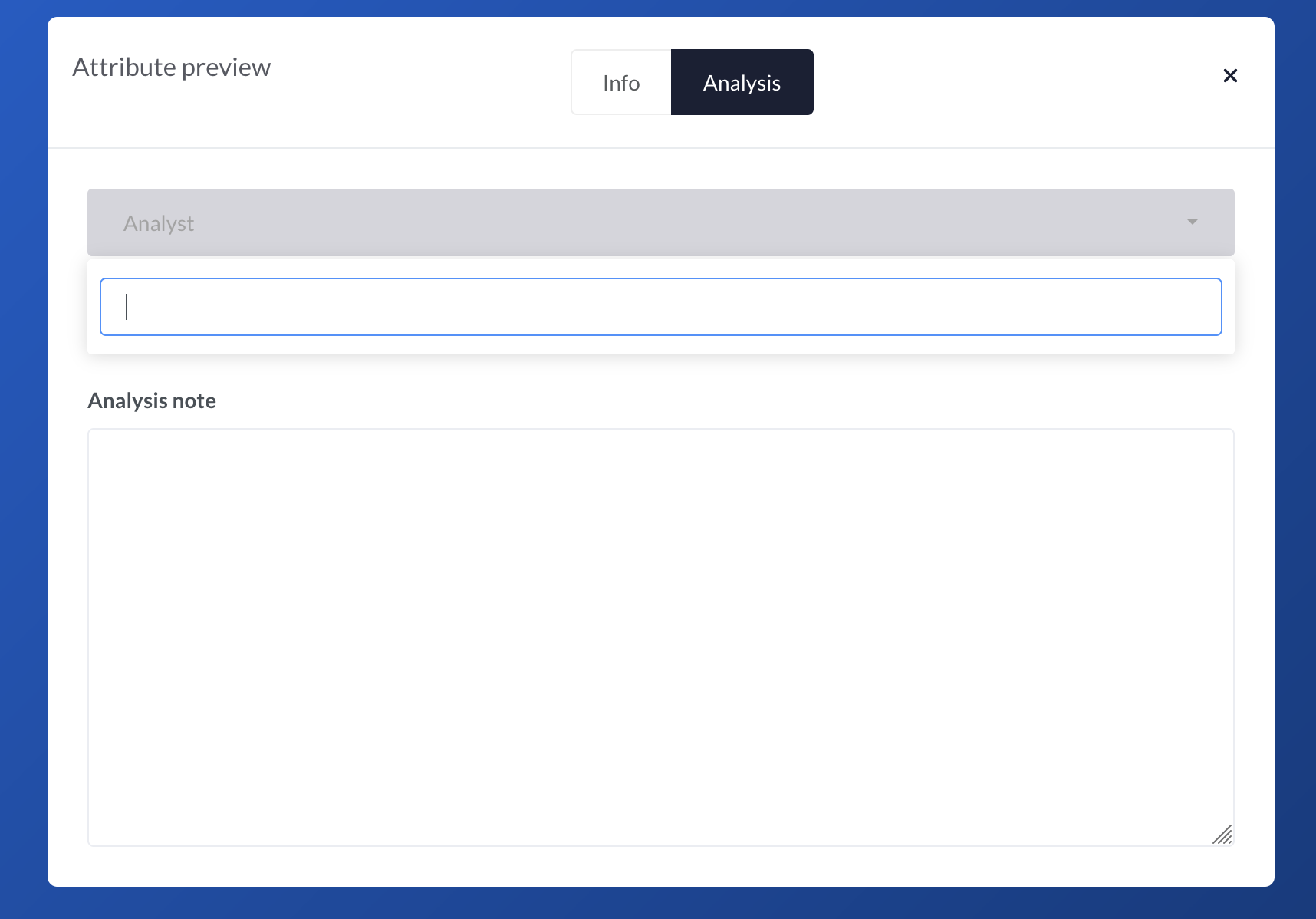
Nice, we can now add raw HTML to our custom attribute. IRIS uses Bootstrap to ease the UI/UX interface, so we can directly reuse these components. Let's replace the h3 with a Bootstrap Select.
Note
Unfortunately JSON does not support multiline strings, so to ease the reading we provide a prettified version of the HTML separately, and next to it, the corresponding final Custom Attribute definition.
If you preview this, you'll notice that you see nothing. That's because we need to add some JS to make the select load. First we give the select an ID (evidence_analyst_analysis) so we can reference it in the JS, and then call the SelectPicker JS loader on it.
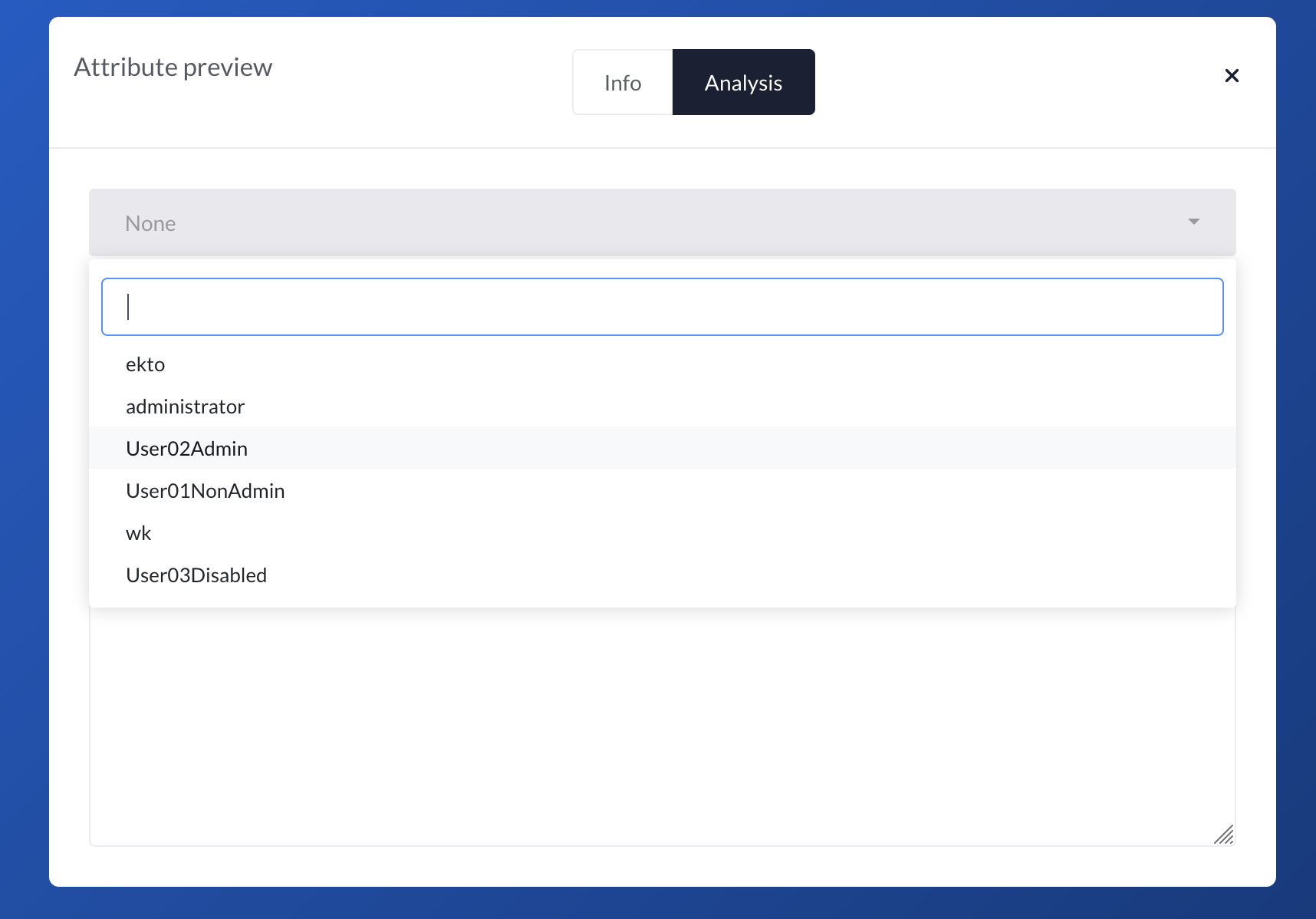
We can now preview it.
Good, we're on the right way!
Requesting external resources
We now need to fill the select picker with the available analysts names. Fortunately, we have an API endpoint for that and we can add some JS to request it and fill our select. There's a few JS glue already written within IRIS, so we're going to use that to ease the writing.
Let's break it down a little.
- Line 2 declares the select picker for our analysts to choose a name from
- Lines 4 to 8 initiate the selectpicker lib on the select, so we have live search, bootstrap theme etc.
- Line 10 asynchronously requests the API endpoint to get a list of the users
- Lines 11 to 15 is a promise that is called upon request completion, add the users options to the select and finally refresh the select with the newly added options.
If we now look at this new code, we should see the list of analysts.
We are getting close! Now, if you deploy these changes and try to save the information of our tab, you'll see that it doesn't work and only the Analysis note and Has been analyzed fields are saved. The Analyst information is lost.
That's because HTML custom attributes cannot be saved by users, otherwise this would open the platform to a multitude of vulnerabilities. Please see section Values saving for more information.
What we can do instead, is add a new input field and use it as a saving mechanism.
Saving values with HTML fields
So let's add an input_string field named User ID in our custom attribute, just below the HTML one. This should look like this.
Now, the idea is to detect a change in the dropdown, put the value in the new input_string field to save our data. And then upon load, check the value in the input field and select the corresponding value in the dropdown.
But how can we know the ID of the new input field we created?
The generator actually uses a convention, and the field will always have the same name if it stays at the same position in the custom attribute. If you save the current attribute and check the ID of the field with the browser debugger, you will see inpstd_2_user_id (i.e standard input in position 2 named user id).
So we can now use this ID and build up our JS.
- Disable the new input field so the users don't mess with it unintentionally
- Get the current value of the input in case the analyst is already set
- If the analyst is already set, then set the analyst ID in our Select as default
- Refresh the Select so the new values are taken into account
- Whenever the Select is changed, get the selected value and put it into the input field
We can now remove the new lines of this snippet and place it in the value field of our HTML attribute. This is our final custom attribute!
We save and deploy the new custom attribute, and there we are - we can now select a user and save it!
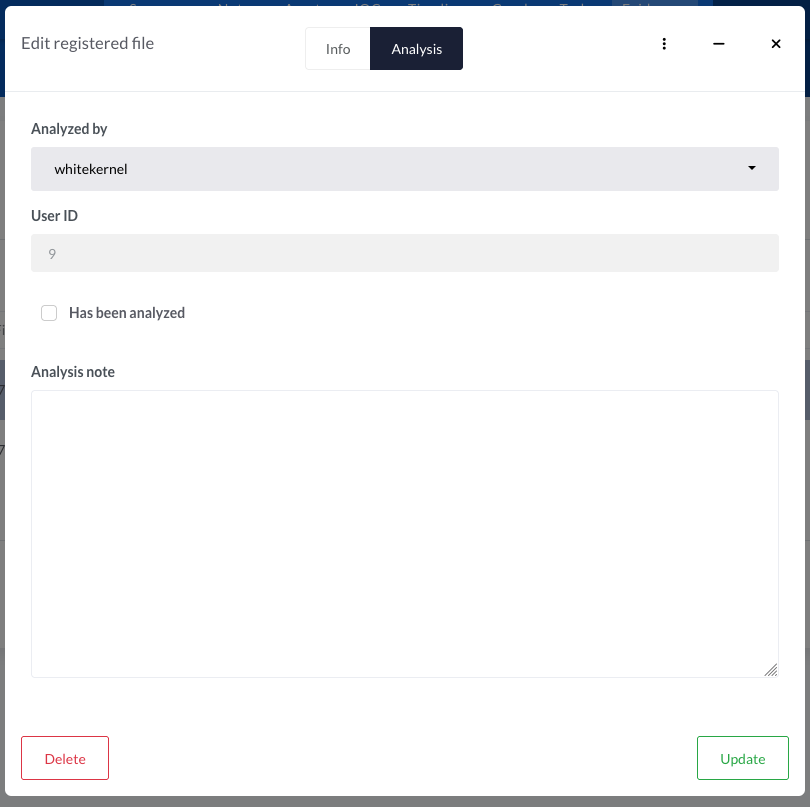
A final note
We have to admit, this was far from trivial . We are currently thinking of new ways to improve these types of specific custom attributes, and they will probably get better over time. In the meantime, we have to trick a little!
Under the hood
So how does custom attributes work under the hood? It's actually simpler than writing one as we did above.
Each case objects table in the DB holds a custom_attributes field, which is of type JSON. For instance, below is the DB declaration of the Notes.
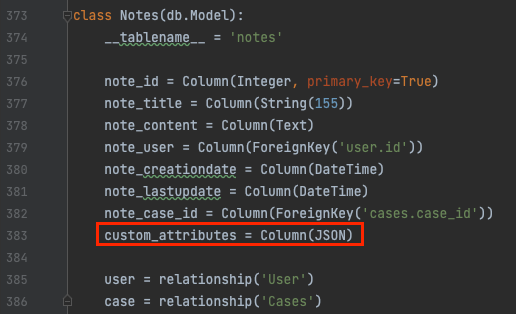
When a custom attribute is created, let's say for Notes, IRIS loops over all existing Notes and apply the JSON structure you just wrote. All of the Notes are now holding this custom attribute.
Rendering
When the details for a Note object is requested by a user, either for creation or update, IRIS reads this custom attribute field and then starts to build a visual representation from the JSON. It does so by calling a Jinja templated HTML piece and then add this piece to the rest of the standard Note object.
This Jinja template is in source/app/templates/modals/modal_attributes_tabs.html.
Let's break it down and simplify it.
The templates loops over all attributes in the custom attribute JSON definition, and depending on the type of field, write a corresponding HTML tag.
You may notice that line 18, the HTML type directly writes the value on the template. That's what allows us to write raw HTML with Javascript!
Values saving
Now, when the data is saved in the object, the client sends a JSON containing the original objet fields, as well as the custom attributes information.
With the example in Basic Example, let's take a look on what happens when the data is saved.
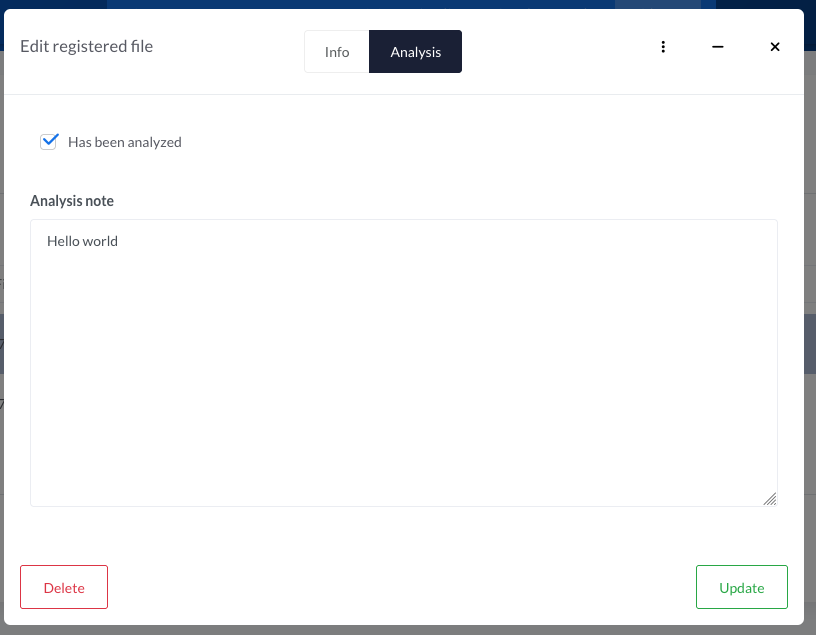
Looking at the request emitted upon Update, we can see a POST towards case/evidences/update/XX. This is the update endpoint. The payload of the request contains the standard fields of the Evidences, as well as the custom attributes.
Evidence update POST payload | |
|---|---|
Lines 7 to 12 contains the new values of the custom attributes.
When receiving the data, IRIS operates a merge.
- Loads the current custom attribute JSON of the Evidence
- Loops over the received data in
custom_attributes - Searches for a tab named
Analysisin the loaded JSON - Within it searches for a field named
Analysis note, and sets itsvaluetoHello world - Within the same tab, searches for a field named
Has been analyzedand sets itsvalueto true. - Saves the JSON back in the Evidence. The data is saved!
Now the custom attribute field of the Evidence looks like this :
Security note
Let's consider an HTML field such as follow :
Malicious Evidence update POST payload | |
|---|---|
This would let the user rewrite the HTML attribute in the Evidence object. The next time another user requests this Evidence, IRIS would read the value of the attribute Analysis header, renders the malicious payload and presents it to this user.
To avoid this, HTML field types are read-only for users. They can't update them.
And we're done for this deep dive!
That's a long one, but hopefully this brings some lights on how the custom attributes are working behind the scene.
Don't hesitate to contact us, should you have any questions or remarks.